框架
整体框架
此框架并不一定是实践中的最佳版本,仅基于个人这段时间学习的认知,后续会不定期修正。
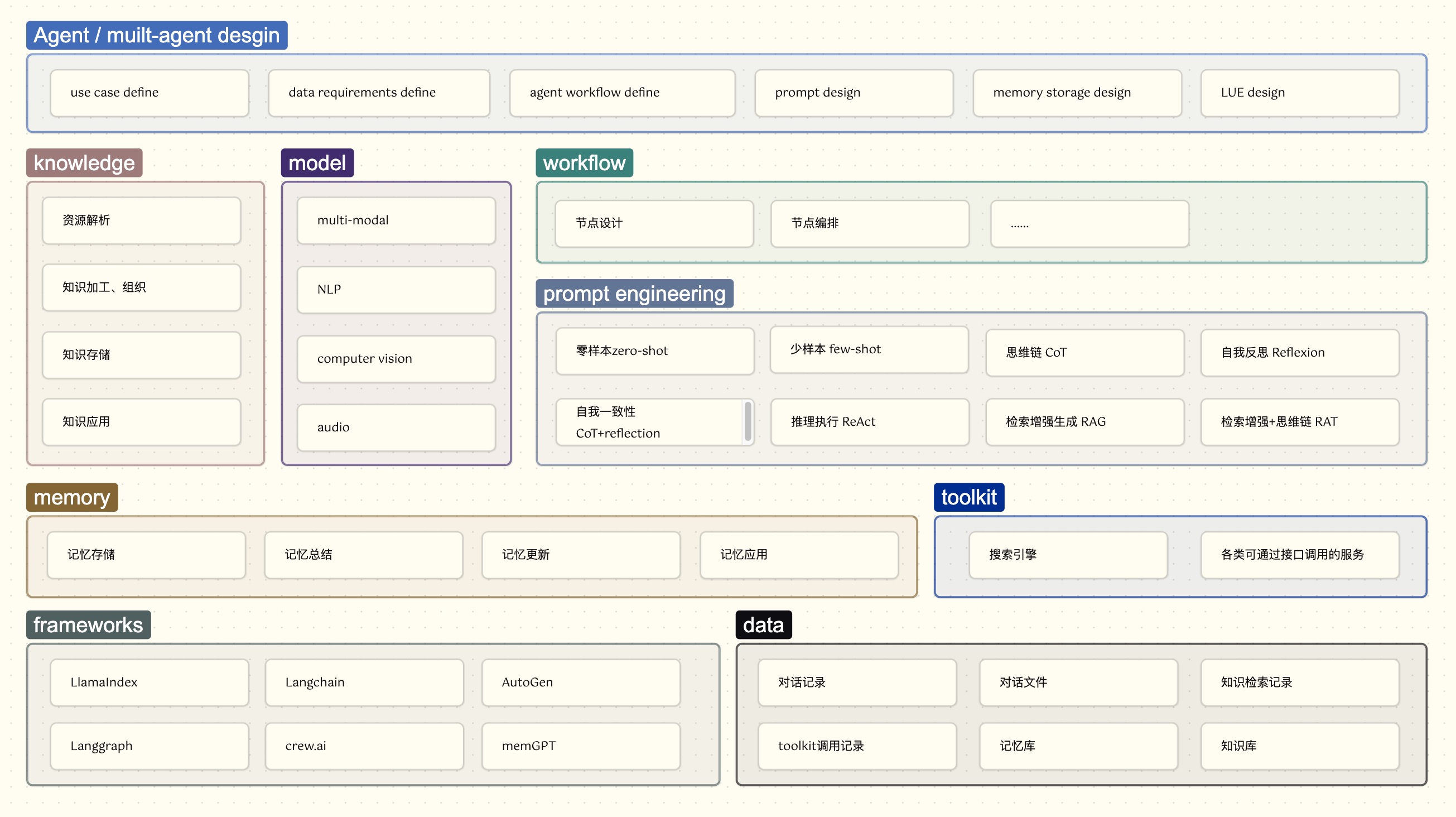
注:此框架并未包括狭义的基建层(硬件、网络、计算、数据库等)
分块讨论
基建
开发框架
- Langchain:Langchain提供了一个编排指令、对话和模型的框架,以链的方式,将材料组织起来,引导大语言模型给出理想答案,核心包括模型I/O,RAG和链
- Langgraph:在chain的基础上引入了graph,可以以图的方式编排节点及其流转逻辑。Langgraph的图并非有向图
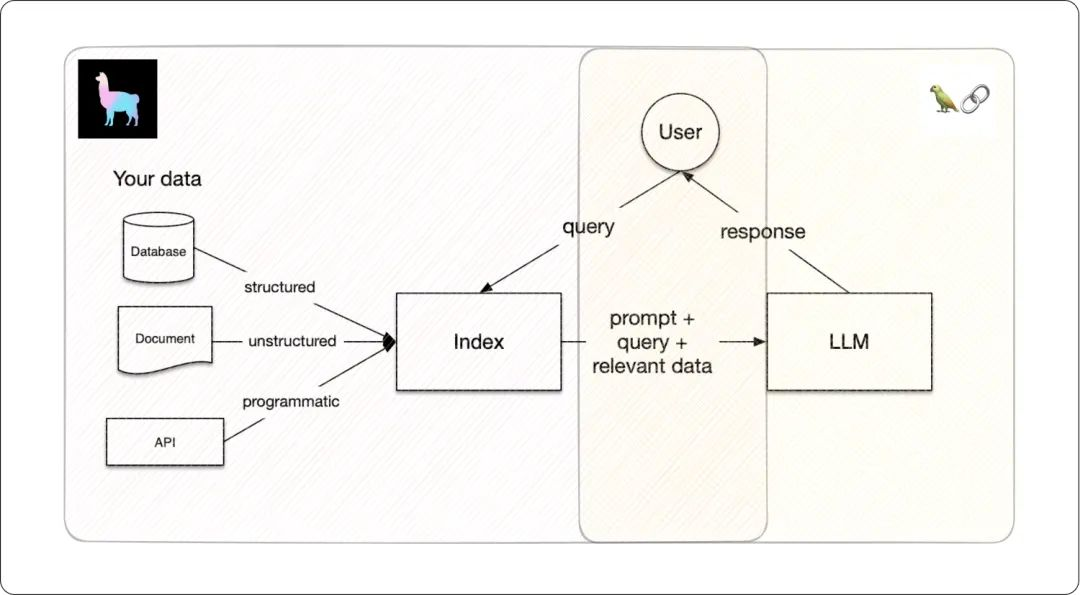
- LlamaIndex:与Langchain不同,LlamaIndex更关注如何将数据层与模型层连接起来,提供了多种类型数据的检索方式
- Autogen:微软的multi-agent框架,可以基于它构建多智能体的生态系统,依赖多智能体的协作解决复杂问题
数据
数据包括供agent使用的数据,也包括产生于用户与agent互动后产生的数据。
- 使用数据
- 对话记录:user、时间、输入及输出、metadata、用户反馈、关联的检索或调用记录等
- 对话文件:用户在对话中上传的文件,模型生成的文件
- toolkit调用记录:工具箱中各种API的调用记录
- 知识检索记录:知识库的检索记录(检索内容、返回结果)
- 记忆记录:记忆的检索、更新、调用记录
- 知识数据
- 知识库
- 记忆数据
- 长期记忆 long-term memory
- 短期记忆 short-term memory
构成单元
模型
- 多模态模型 multi-modal
- Llava
- GPT4v
- Clip
- ……
- 自然语言理解模型 NLP
- GPT4 (OpenAI)
- mistral 7b 13b .. (Mistral AI)
- mixtral 7b 8X22b .. (MoE model by Mistral AI)
- Qwen 7b 13b .. (Alibaba)
- Llama2 7b 13b .. (Meta)
- Llama3 8b 70b .. (Meta)
- chatGLM 6b .. (zhipuai)
- ……
- 计算机视觉 computer vision
- stable diffusion (stability AI)
- ……
- 语音 Audio
- whisper(OpenAI)
- bark(Suno)
- ……
prompt工程
prompt工程是LLM应用的特有编排手段,它依赖LLM的能力来进行问题理解、目标设定、分步实施和给出反馈。agent设计中,我们期待引入toolkit、记忆和知识来优化反馈效果,而如何让模型理解问题、确定目标、知道自己有哪些资源、何时以何种方式利用资源、执行并反馈结果,是最大的难点。
以下是prompt工程领域的若干典型方法:
- 零样本 zero shot:无参考样本,仅提出指令,要求模型自行理解并执行
- 少样本 few shot:给少数样本,并配以指令,要求模型理解指令、样本的逻辑,并执行
- 思维链 CoT:明确解决问题的思路,要求模型按明确的思路进行思考,逐步推理,得到答案(看似类似工作流的定义,但非常考验编写者自己的抽象能力)
- 检索增强生成 RAG:引导大模型检索知识、记忆,基于检索到的内容进行回答
- 自我反思 Reflexion:引导大模型不断地进行反思,得到一个收敛的答案
- 推理执行 ReAct:给出若干包含行为逻辑的样本,要求模型理解逻辑并复制到自己的思维中,进行答案推理
- ……
工作流
为agent应用定义工作流涉及节点的定义和编排,而这些节点可以使用底层框架通过代码来实现,也可以基于dify、flowise这样的平台,通过低码方式配置,不同的平台可能对节点类型有不同的细分。
工作流是prompt工程之外,引导模型输出的另一个手段:通过固定工作流,对于特定的内容进行深入加工和输出。但设计时需要通盘考虑token消耗、时间消耗等。
工作流的设计内容主要包括以下:
- 节点定义:节点即包含了输入、输出和加工方式的处理单元,常见的节点类型包括LLM节点、API调用节点、知识检索节点、数据库检索节点、消息发送节点等
- 节点编排:也即将节点组合并编排起来,除单向流程之外,还可以设置循环、条件等特殊流转方式
注:通过工作流得到耗费更多时间的agent设计,在最终的用户体验上,并不一定会优于prompt和RAG,实际应用中需要谨慎测试。
记忆
构建记忆的目的不是单纯的匹配检索,而是理解对话者。对于个人服务场景的agent来说,记忆尤其重要:agent忘记了对话者的信息的时刻,就是对话者意识到对面是个机器人,进而削减信任度的时刻。
当然记忆还有另一个作用:减少token消耗,优化整体效率。
不同的框架提供了不同的记忆管理方式,就Langchain来说,它定义了对话缓存记忆(可以理解为短期记忆)和总结记忆(经过大模型总结的对话记忆,可以理解为长期记忆),前者事无巨细,后者只有重点,而为了补足后者缺失细节的不足,还引入了对话总结缓存记忆(当对话窗口过长之后,不会删除久远的记忆,而是触发新一轮的总结),这样就能实现:保留久远的、缺失细节的长期记忆用于检索,同时将最近的、清晰的短期记忆用于对话。
记忆的管理方式,与agent的用例强相关,也同时依赖于模型、数据存储和检索等基础能力单元。记忆管理一般可分为以下几点:
- 记忆存储:存储记忆。选择存储方式的时候需要考虑后续使用场景中对记忆的调用和检索方式,例如是否需要能够直接通过关键词定义对话内容(关系型数据库的检索方式)。
- 记忆更新:更新与简单存储不同,前者涉及主题、实体的识别及关系网络的建立。记忆的更新方式更接近知识图谱,而非记录的简单叠加。更新记忆的目的是,完整地理解对话者及其所处的时空:不以时间的远近来限制记忆检索的范围,当涉及同一对象时,像铅笔描线一样,加深、扩展或更新关于这个对象的信息,从而得到关于对话者及世界的立体模型,模型中的每一个事物都有其时间和空间上的厚度。
- 记忆总结:为了在保留记忆的同时提升检索效率,可以对长远的对话内容进行压缩,提取长期记忆,保存下来,还可以设计记忆的衰减。像是人脑一样,遵循peak-end rule。
- 记忆调用:检索记忆。
知识
如果说记忆是为了理解对话者,知识则是为了让agent向对话者提供指定的内容(或者说提供更好的服务)。
知识加工的过程可以使用LLM的能力,知识加工和组织的结果可以与LLM通过prompt工程进行组合。在agent设计的场景中,知识与模型是独立的。
管理知识主要包括以下几点:
- 资源解析:基于文件读取、OCR等技术,读取原始资源,解析得到合适的结果,例如区分图片、文本段落、表格,并以合适的方式进行转换呈现。
- 知识加工、组织:基于解析结果,进行清洗、加工、抽取,并将知识围绕目标场景和用例,选择合适的方式组织起来,构建关联关系,丰富知识及知识组织的元数据。
- 知识存储:选择合适的方式存储知识,基于用例、框架和知识的组织方式,以合适的方式存储知识。
- 知识调用:检索记忆。
工具箱
各种API
Agent设计
用例定义
相比于一般意义上的用例,Agent应用的用例需要分为两大类:界面交互用例和对话场景用例,其中对话场景用例有点类似于模型测试的测试集。
- 界面交互用例:在LUI或CUI中,用户与agent可产生的交互
- 场景用例:基于agent的目标,分析工作场景中会发生的情况,定义典型案例
数据需求定义
定义为了达成目标,agent所需的信息,主要包括:
- 哪些信息:哪些信息是需要引入的
- 如何组织:这些信息或知识应当如何组织起来才能够达到最优效果
- 如何引入:这些知识应当如何引入human-agent的生态环境中
- 如何结合:引入时,应当如何与模型、prompt、api及底层框架、数据库结合起来
工作流设计
针对复杂而关键的问题,通过节点的定义和编排,引入更多的可控性,人工地向LLM无序、不可控、不可见的“思维”中引入明确的加工链条,一旦能够成功触发,就大概率能够按既定流程得到限定的输出。
记忆管理方式设计
基于agent的工作场景,为agent设计记忆,有以下几点需要考虑:
- 是否需要长期记忆
- 短期记忆的窗口长度
- 何时需要对记忆进行更新和压缩
- 何时触发对长期记忆的检索,检索时限制时间和检索逻辑是怎样的
prompt设计
如前面所说,prompt实际是一种编排方式,是一个指令集,指令集应当在前面的内容全部确定之后,再作设计。
prompt的设计有一些基础准则:
- 编写清晰、具体的指令
- 使用分隔符清晰地表示输入的不同部分:分隔符可以是:
```、""、<>、\<tag><\tag>、:等。 - 要求一个结构化的输出:结构化输出可以是 JSON、HTML 等格式,这样可以使模型的输出更容易被我们解析。
- 要求模型检查是否满足条件:当要求模型完成一系列任务,而任务的假设并不一定满足时,可以要求模型拆解任务步骤,明确每一步的假设前提,并告诉模型先检查这些假设,如果不满足就停止执行并给出提示。当然也可以补充潜在的边缘情形,让模型合理地处理。
- 提供少量的示例(few-shot):在模型执行之前,为它提供少量正确的案例。
- 使用分隔符清晰地表示输入的不同部分:分隔符可以是:
- 给模型时间去思考:为了减少错误答案的产生,可以让模型在给出最终的答案前进行一系列相关推理,指示它多花一些时间思考。
- 指定完成任务所需的步骤:对于复杂任务,给出完成该任务的一系列步骤,同时明确输出要求,让模型按步骤执行
- 指导模型在下结论之前找出一个自己的解法
用户交互体验设计
基于agent的使用场景,需要进行一定的交互体验设计,包括界面、卡片、字体、气泡等。
交互体验依然是重要的一环,一方面是为了实现agent的最优服务效果,另一方面是为了弥补或平衡由于模型、工作流、prompt等带来的不稳定反馈。
实现
框架是一个静态的内容,而框架内所有的组成部分都应当加上时间,也即放到实际的生产环境考虑,并考虑成本和收益,以求达到最佳平衡。
预备在后续一到两个月的时间里,按模块划分,面向生产地,做以下探究和产出,期间不断优化框架:
- 开发框架:特性,特性对比,讨论不同的框架如何互相结合。
- 模型:整理主流模型,并进行对比。不仅仅对比具体模型,还可对比不同的模型架构。
- 知识管理:如何对知识进行管理,包括知识的获取、治理、存储和应用,探索生产环节的知识赋能逻辑。
- 记忆管理:如何对记忆进行管理,主要包括如何存储、更新、压缩和调用。需要深入研究memGPT等对agent记忆有侧重的框架,同时参考脑科学对于人类记忆的理解。
- prompt工程:
- 基础:零样本、少样本、CoT案例;结合dify,coze等工具实践。
- RAG:实现逻辑,与知识、记忆的结合要点,与大模型能力的关系;尝试工程化实践:结合Xinference,Langchain,RAGflow等工具或框架。
- ReAct:实现逻辑,与大模型能力的关系,与知识的结合要点。
- 工具箱:引入,管理,与prompt结合,与大模型能力的关系。
- 工作流:实现逻辑,编排思路,探索如何取得准确和效率的平衡。
- agent设计:定义agent或agent群组的目标,定义用例和数据需求,定义实现逻辑。